Working with large datasets in Deepof
(For the test version, this tutorial is currently only attached to the custom labels tutorial (to make them run with out automatized tests without having to restructure a ton of stuff). It will stand on its own later)
What we’ll cover:
How to process large datasets (several hours of recording per video) with deepof
Things to consider when working with large quantities of data
[1]:
# # If using Google colab, uncomment and run this cell and the one below to set up the environment
# # Note: because of how colab handles the installation of local packages, this cell will kill your runtime.
# # This is not an error! Just continue with the cells below.
# import os
# !git clone -q https://github.com/mlfpm/deepof.git
# !pip install -q -e deepof --progress-bar off
# os.chdir("deepof")
# !curl --output tutorial_files.zip https://datashare.mpcdf.mpg.de/s/Hu1XjZkY9zml0mm/download
# !unzip tutorial_files.zip
[2]:
# import os
# os.chdir("deepof")
# import os, warnings
# warnings.filterwarnings('ignore')
We start with importing the usual packages
[3]:
import copy
import os
import numpy as np
import pickle
import deepof.data
And plotting gear
[4]:
from IPython import display
from networkx import Graph, draw
import deepof.visuals
import matplotlib.pyplot as plt
import seaborn as sns
Brief introduction to large dataset analysis
In general, analysing very large datasets works, on a user level, almost the same as analyzing small datasets. The main difference is that
Things take longer
Tables do not stay loaded in the RAM, but instead get saved and loaded in the background as tehy are needed
The latter leads to the ubiquitous Table dictionaries in deepof now carrying only links to file locations instead of the tables themselves.
For this tutorial we do not provide an additional “big” dataset (as we do not want you to wait several hours for a downlaod). Instead we are going to load the same sample_project as in the unsupervised tutorial. Then we simply manually set the “_very_large_project” project-variable to True, which will cause the project to behave just like it would if it had videos with multiple hours long of recordings.
If you create your own project with a larger dataset (i.e. at least one video that is about 4 hours long or longer) this variable will simply be automatically set to True during project set up.
[5]:
# We load our small sample project, then we pretend that it is a big one
my_deepof_project = deepof.data.load_project("./tutorial_files/sample_project")
my_deepof_project.load_exp_conditions("./tutorial_files/tutorial_exp_conditions.csv")
my_deepof_project._very_large_project=True
Now let’s create some supervised annotations
[6]:
supervised_annotation = my_deepof_project.supervised_annotation()
data preprocessing : 100%|██████████| 4/4 [00:11<00:00, 2.92s/step, step=Loading kinematics]
supervised annotations : 100%|██████████| 6/6 [00:12<00:00, 2.10s/table, step=post processing]
If we now try to have a look at one of our tables that we created we notice a difference: Instead of seeing the table, deepof now only displays the path to the file in which thsi table was stored.
[7]:
supervised_annotation['20191204_Day2_SI_JB08_Test_54']
[7]:
{'duckdb_file': './tutorial_files\\sample_project\\Tables\\20191204_Day2_SI_JB08_Test_54\\database.duckdb',
'table': 't_20191204_Day2_SI_JB08_Test_54_supervised_annotations'}
If we want to load this table we can access it with the “get_dt” function and a syntax very similar to calling a dictionary entry
[8]:
deepof.data_loading.get_dt(supervised_annotation,'20191204_Day2_SI_JB08_Test_54')
[8]:
| B_W_nose2nose | B_W_sidebyside | B_W_sidereside | B_W_nose2tail | W_B_nose2tail | B_W_nose2body | W_B_nose2body | B_W_following | W_B_following | B_climb-arena | ... | W_stat-lookaround | W_stat-active | W_stat-passive | W_moving | W_sniffing | W_distance | W_cum-distance | W_speed | B_missing | W_missing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000 | 0.0000 | 0.00000 | 0 | 0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000 | 0.0000 | 0.00000 | 0 | 0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000 | 0.0000 | 0.00000 | 0 | 0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000 | 0.0000 | 0.00000 | 0 | 0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 4.140 | 4.1400 | 103.45860 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14994 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.070 | 42787.8236 | 1.74930 | 0 | 0 |
| 14995 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.067 | 42787.8906 | 1.67433 | 0 | 0 |
| 14996 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.051 | 42787.9416 | 1.27449 | 0 | 0 |
| 14997 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.037 | 42787.9786 | 0.92463 | 0 | 0 |
| 14998 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.025 | 42788.0036 | 0.62475 | 0 | 0 |
14999 rows × 33 columns
We also can retrieve only some meta information (like the column names, the number of rows and columns and such) as a dictionary by sligthly modifying our call
[9]:
deepof.data_loading.get_dt(supervised_annotation,'20191204_Day2_SI_JB08_Test_54', only_metainfo=True, load_index=True)
[9]:
{'columns': ['B_W_nose2nose',
'B_W_sidebyside',
'B_W_sidereside',
'B_W_nose2tail',
'W_B_nose2tail',
'B_W_nose2body',
'W_B_nose2body',
'B_W_following',
'W_B_following',
'B_climb-arena',
'B_sniff-arena',
'B_immobility',
'B_stat-lookaround',
'B_stat-active',
'B_stat-passive',
'B_moving',
'B_sniffing',
'B_distance',
'B_cum-distance',
'B_speed',
'W_climb-arena',
'W_sniff-arena',
'W_immobility',
'W_stat-lookaround',
'W_stat-active',
'W_stat-passive',
'W_moving',
'W_sniffing',
'W_distance',
'W_cum-distance',
'W_speed',
'B_missing',
'W_missing'],
'num_cols': 33,
'num_rows': 14999,
'shape': (14999, 33),
'index_column': Index(['00:00:00', '00:00:00.040002666', '00:00:00.080005333',
'00:00:00.120008', '00:00:00.160010667', '00:00:00.200013334',
'00:00:00.240016001', '00:00:00.280018667', '00:00:00.320021334',
'00:00:00.360024001',
...
'00:09:59.599973331', '00:09:59.639975998', '00:09:59.679978665',
'00:09:59.719981332', '00:09:59.759983998', '00:09:59.799986665',
'00:09:59.839989332', '00:09:59.879991999', '00:09:59.919994666',
'00:09:59.959997333'],
dtype='object', length=14999),
'start_time': '00:00:00',
'end_time': '00:09:59.959997333'}
Plotting the data can be done in the same way as with small datasets. All plot functions have the optional input “samples_max” which denotes the maximum number of samples plotted and is set to 20000 for most plots as a default. So do not be afraid of excessive waiting times when plotting. Let’s have a look at the Gant plot as an example:
[10]:
plt.figure(figsize=(12, 8))
deepof.visuals.plot_gantt(
my_deepof_project,
"20191204_Day2_SI_JB08_Test_54",
supervised_annotations=supervised_annotation,
)
plt.show()
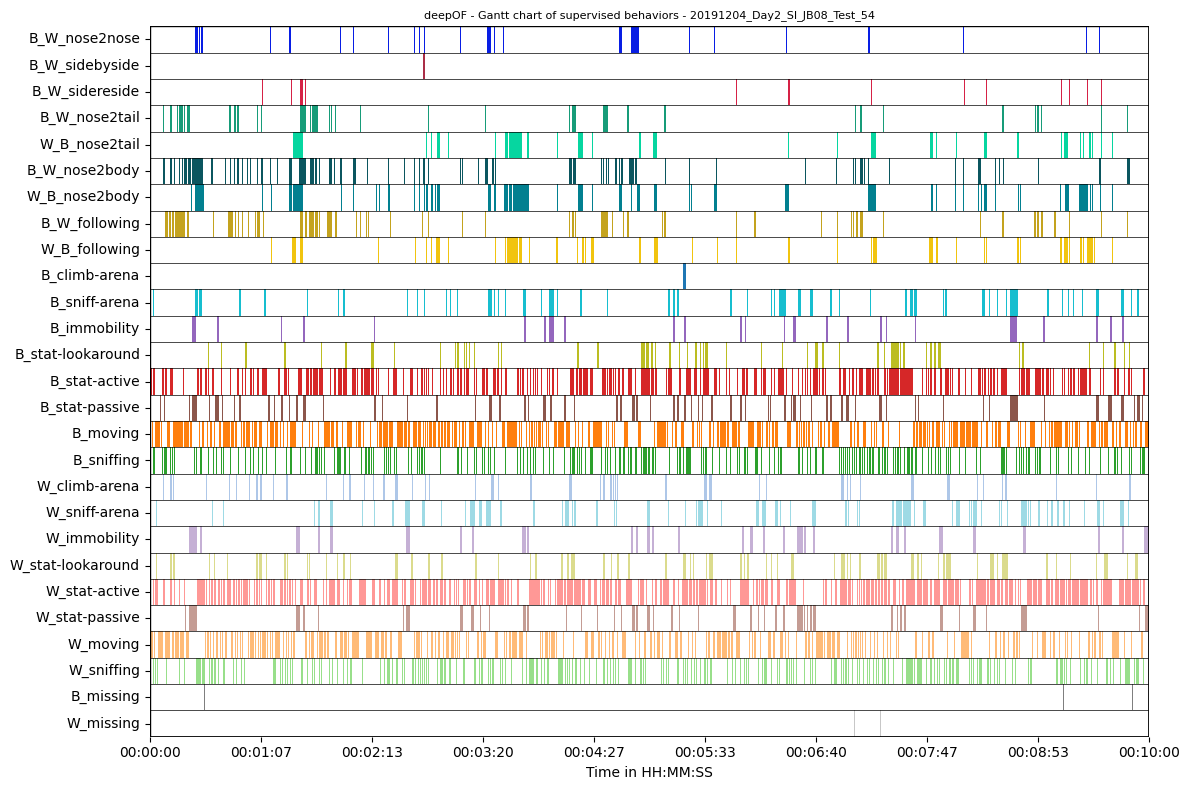
Of course, plotting only a fraction of the samples that your data actually contains will lead to a reduced resolution of the plot and can be misleading. Let’s say one behavior only occurs every 100 frames but pretty regularly. If the plot gets downsamples by a factor of 100 it may happen that the included samples are mostly the ones where this specific behavior occurs. Respectively in the downsampled plot it will seem as this behavior is way more frequent than it actually is.
[11]:
plt.figure(figsize=(12, 8))
deepof.visuals.plot_gantt(
my_deepof_project,
"20191204_Day2_SI_JB08_Test_54",
supervised_annotations=supervised_annotation,
samples_max=500,
)
plt.show()
Info! Selected range exceeds 500 samples and has been downsampled by a factor of approx. 29
To avoid this, increase 'samples_max'. This will also result in increased computation time
Warning! Since the provided time bins contain gaps, the time range below may be incorrectly displayed!
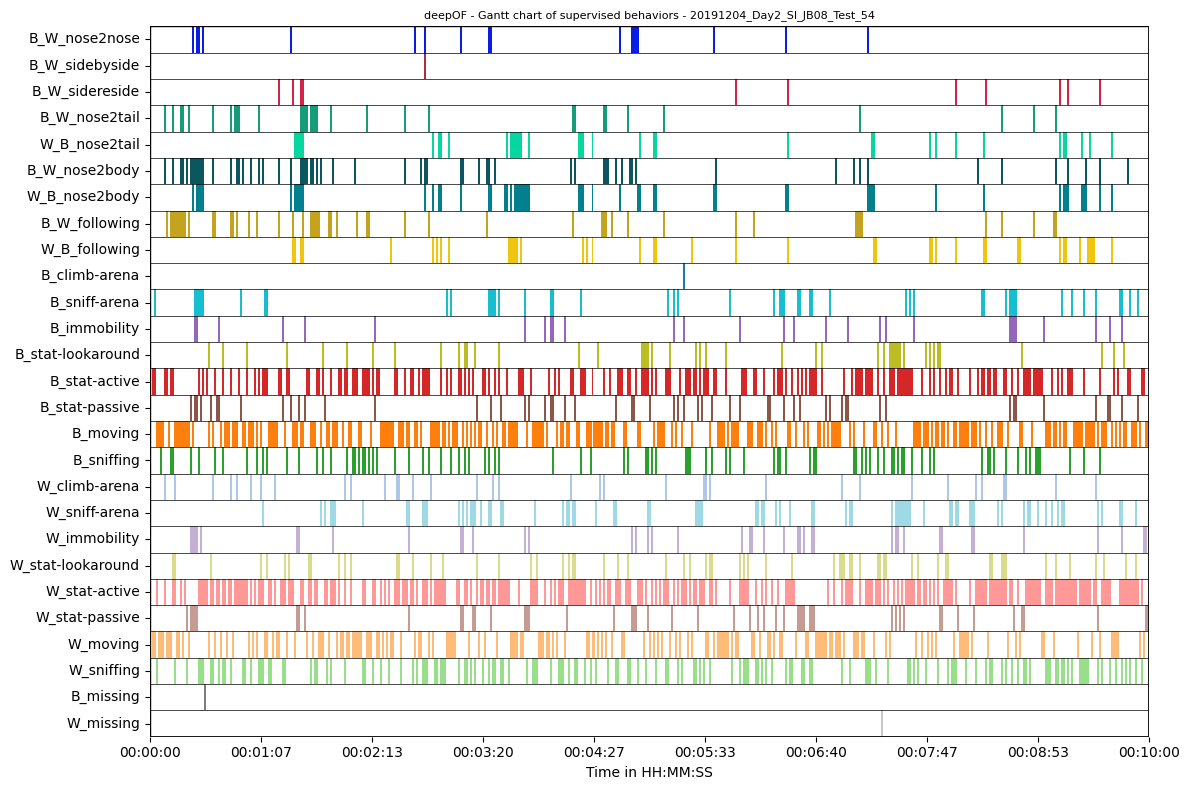
Respectively for large datasets it becomes especially relevant to also look at sections of your plots. You can do this with the bin_index and bin_size inputs providing either bin numbers and sizes (with the size being given in seconds) or start times and durations. Let us plot only the second minute of the gantt plot with both notations.
[12]:
sns.set_context("notebook")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 6))
deepof.visuals.plot_gantt(
my_deepof_project,
"20191204_Day2_SI_JB08_Test_54",
supervised_annotations=supervised_annotation,
bin_index=1,
bin_size=60,
ax=ax1
)
deepof.visuals.plot_gantt(
my_deepof_project,
"20191204_Day2_SI_JB08_Test_54",
supervised_annotations=supervised_annotation,
bin_index="0:01:00",
bin_size="0:01:00",
ax=ax2
)
plt.show()
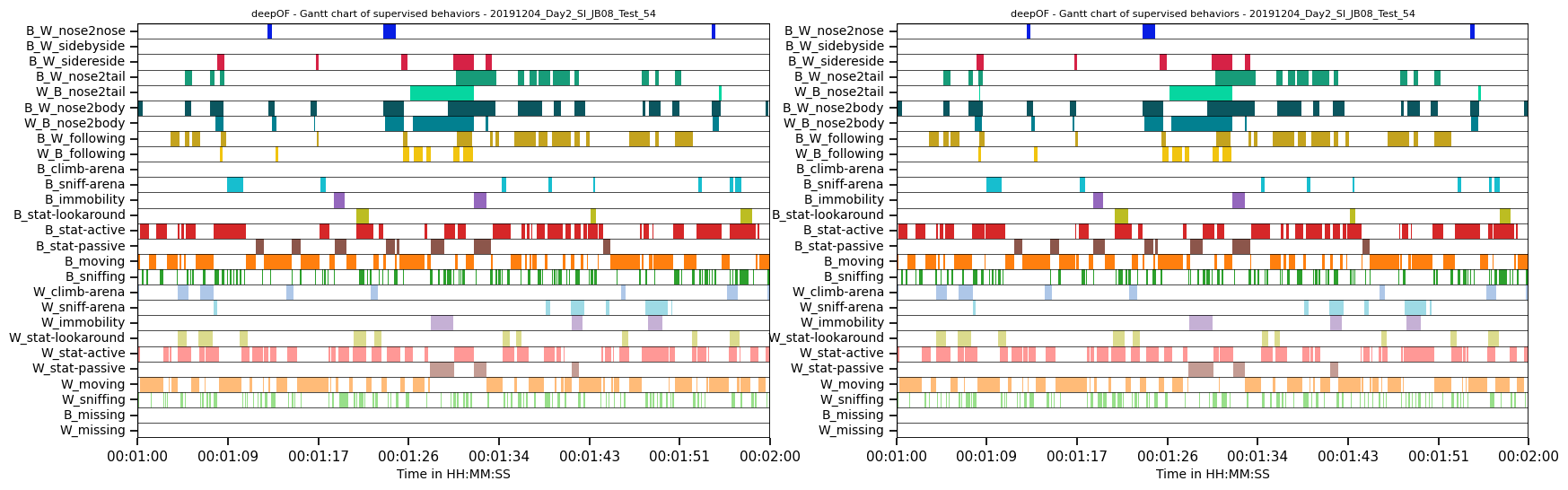
We also can compare one specific behavior accross all of our experiments. This becomes especially relevant when working with large datasets and having mice missing for longer periods of times (because tehy are sleeping in their shelters). You can do this by simply calling the Gantt plot with a behavior instead of the key for a specifiv experiment:
[13]:
plt.figure(figsize=(12, 8))
deepof.visuals.plot_gantt(
my_deepof_project,
"B_missing",
supervised_annotations=supervised_annotation,
)
plt.show()
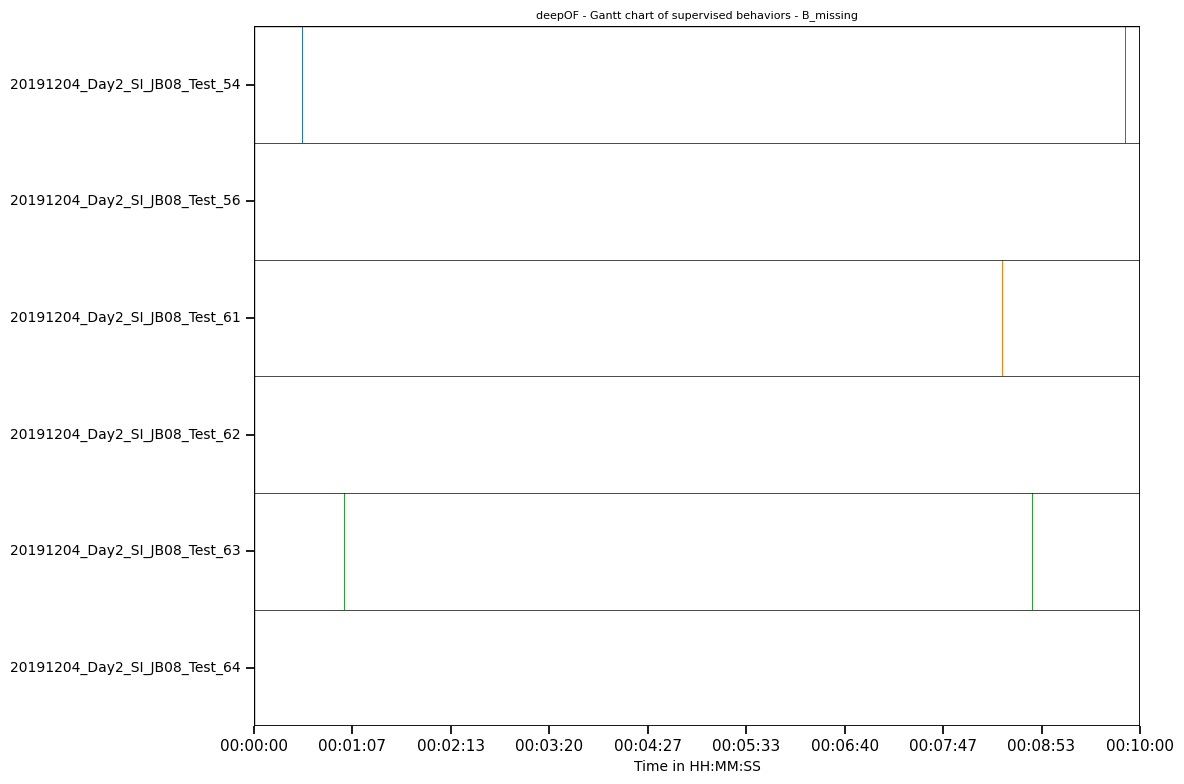
Since this experiment is only 10 minutes long there where no times where the mice were sleeping, but I think you get the point.
Let’s say we now identified a good section where all mice are active. In this case it does not really matter but let’s take the second minute as an example. If we want to train a model to see if there are any differences, we can do as we learned in the unsupervised pipeline tutorial. The only difference is that we only extract graph data from a section of our data in this case, using the bin_index and bin_size arguments again.
[14]:
# This code will generate a dataset using graph representations, as well a some auxiliary objects
graph_preprocessed_coords, shapes, adj_matrix, to_preprocess, global_scaler = my_deepof_project.get_graph_dataset(
animal_id="B", # Comment out for multi-animal embeddings
center="Center",
align="Spine_1",
window_size=25,
window_step=1,
test_videos=1,
preprocess=True,
scale="standard",
bin_index="0:01:00",
bin_size="1:01:00",
)
Loading tables : 100%|██████████| 5/5 [00:06<00:00, 1.30s/step, step=Get graph info]
Sampling : 100%|██████████| 6/6 [00:00<00:00, 12.11table/s]
Scaling : 100%|██████████| 6/6 [00:02<00:00, 2.54table/s]
Get training windows : 100%|██████████| 5/5 [00:04<00:00, 1.21table/s]
Get testing windows : 100%|██████████| 1/1 [00:00<00:00, 1.21table/s]
Reshaping : 100%|██████████| 2/2 [00:06<00:00, 3.15s/table]
[For 20191204_Day2_SI_JB08_Test_54 and possibly others]: Chosen time range exceeds signal length. Bin size was truncated to 00:09:00.216086435.
NOTE: If you do not select custom bins for very large datasets, only a down sampled version from all of your data is used dependent on the working memory you have available. This is often undesirable as it will result in gaps between frames and the inclusion of suboptimal intervalls, such as sleeping periods.
Now we can train our model and extract the embeddings just as in the unsupervised pipeline tutorial
[15]:
trained_model = my_deepof_project.deep_unsupervised_embedding(
preprocessed_object=graph_preprocessed_coords, # Change to preprocessed_coords to use non-graph embeddings
adjacency_matrix=adj_matrix,
embedding_model="VaDE", # Can also be set to 'VQVAE' and 'Contrastive'
epochs=10,
encoder_type="recurrent", # Can also be set to 'TCN' and 'transformer'
n_components=10,
latent_dim=6,
batch_size=1024,
verbose=True, # Set to True to follow the training loop
interaction_regularization=0.0,
pretrained=True, # Set to False to train a new model!
)
[16]:
# Get embeddings, soft_counts, and breaks per video
embeddings, soft_counts = deepof.model_utils.embedding_per_video(
coordinates=my_deepof_project,
to_preprocess=to_preprocess,
model=trained_model,
animal_id="B",
global_scaler=global_scaler,
)
Computing embeddings : 100%|██████████| 6/6 [01:58<00:00, 19.79s/table]
And whilst none of the generated tables are stored in memory…
[17]:
embeddings["20191204_Day2_SI_JB08_Test_54"]
[17]:
{'duckdb_file': './tutorial_files\\sample_project\\Tables\\20191204_Day2_SI_JB08_Test_54\\database.duckdb',
'table': 't_20191204_Day2_SI_JB08_Test_54_unsup_embed__npy'}
… we can plot with them just as usual
[18]:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
deepof.visuals.plot_embeddings(
my_deepof_project,
embeddings,
soft_counts,
aggregate_experiments=None,
samples=100,
colour_by="cluster",
ax=ax1,
save=False, # Set to True, or give a custom name, to save the plot
)
deepof.visuals.plot_embeddings(
my_deepof_project,
embeddings,
soft_counts,
aggregate_experiments="time on cluster", # Can also be set to 'mean' and 'median'
exp_condition="CSDS",
show_aggregated_density=False,
ax=ax2,
save=False, # Set to True, or give a custom name, to save the plot,
)
ax2.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.0)
plt.tight_layout()
plt.show()
Info! Set colour_by to exp_condition as aggregate_experiments were given!
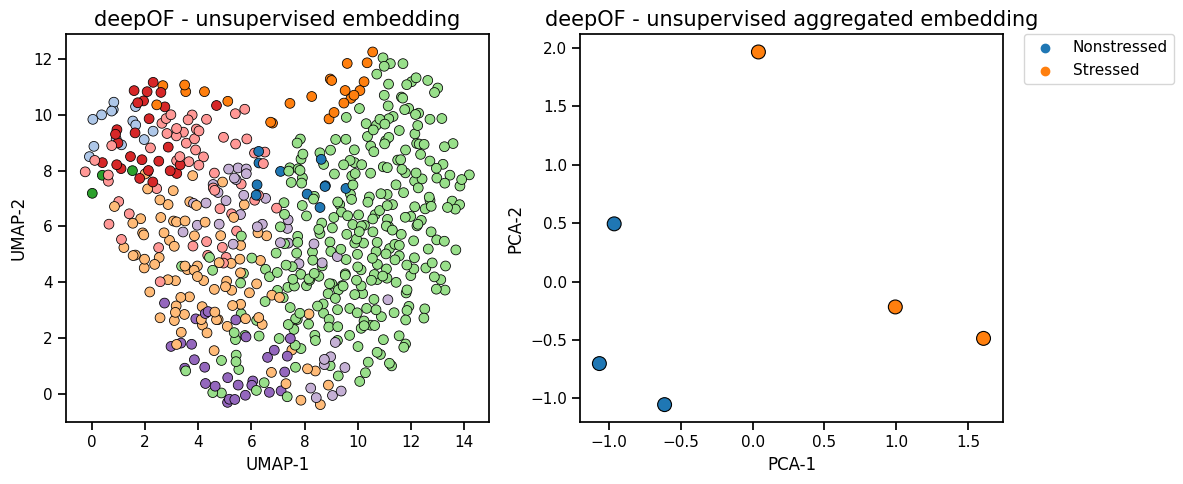
But as you should know, if we train any model on a set of only 6 1-minute long data sets, the results are not meaningful as we just get significant overfitting.